Programming Language and Integrated Development Environment
We will be using the Python programming language for ease of implementation with front-end web development and natural language processing
There exist many libraries and APIs such as NLTK, PyTorch and spaCy that are widely used for NLP related tasks and provide a large amount of support, which, furthermore, will help with learning around the subject area
The Microsoft Azure cloud-based service offers central management for our system code, databases and timed scrapes
Azure functions support data mining related tasks – scraping the RPS database and UCL module catalogues
Web Scraping
First Part: Scraping UCL Module Catalogue
As the first step, it was necessary to gain insight into the extent to which UCL is able to deliver the key ideologies outlined in the 2015 United Nations Sustainable Development Goals (hereafter SDGs) through teaching. Hence, the UCL Module Catalogue was proposed as a data source for natural language processing and categorisation. Initially, the UCL API was used to comprise a unique module link. For example, the API provided module name - “Neurology and Neurosurgery - Basic” and module identification “CLNE0012”, which was then used to concatenate to form a final module link - https://www.ucl.ac.uk/module-catalogue/modules/neuromuscular-literature-review-CLNE0010. The data as such was stored in the all_module_links.json file for future use and can be updated by running the initialise_files.py file in the MODULE_CATALOGUE/INITIALISER directory. Consequently, that unique link was piped into the "BeautifulSoup" Python library to obtain a webpage html file data for all 5576 modules (at the time of conducting the project).

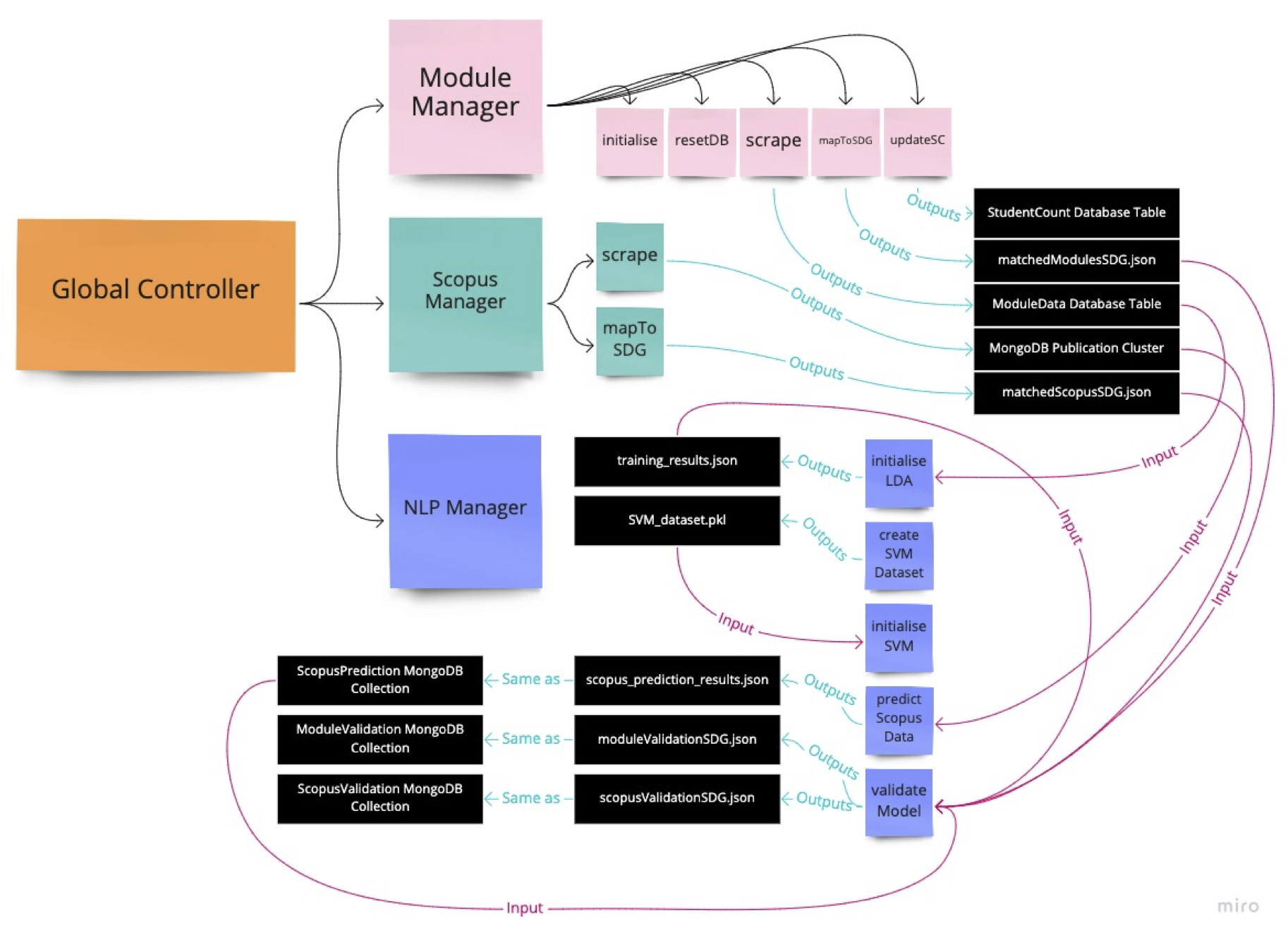
Object oriented programming allowed us for greater control of instantiation, encapsulation and abstraction of data mining scripts. Specifically, it was useful in abstraction of initialisation, specifically, obtaining all module-related and departmental metadata. Thus, by running global_controller.py one may instantiate all necessary files to proceed with the module-to-SDG mapping process. The following data points were obtained: module title, module ID, faculty, department, credit value, module lead name and description. Upon processing each one of those strings into cleaner form, the data was organised into a tuple and stored in a list and pushed to the ModuleData table in the MainDB database using “pyodbc” Python library.
Processing Algorithms
It is worth noting that the processes described below formed a part in a back-up, alternative approach to SDG mapping. Due to an issue with large dataset annotation, it was agreed with our clients that this change was necessary for delivering an improvement into the current classification processes.
UCL Module Catalogue Matching

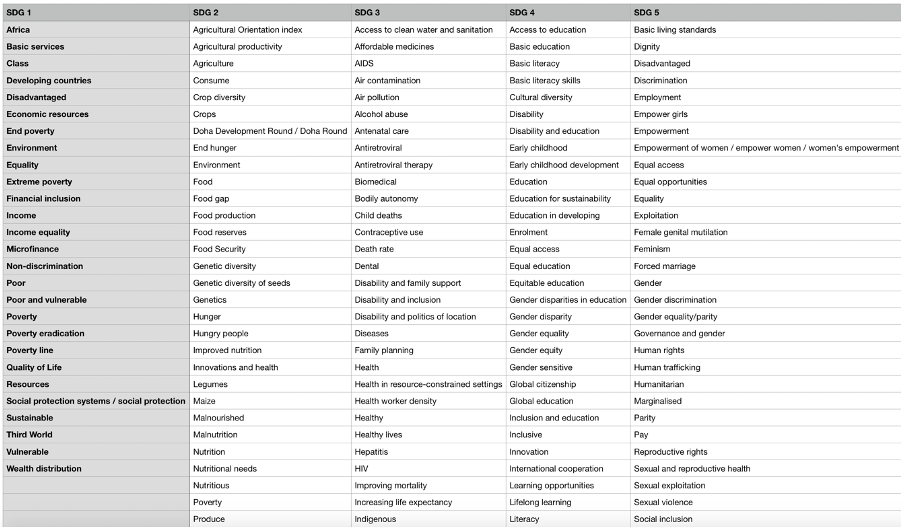
The following process illustrated below demonstrates the algorithm for matching UCL Module Catalogue to sustainable development goals provided in the SDG_Keywords.csv file. The processing file - map.py also pulls the data from ModuleData database table, which contains all data relating to a particular module, including its description, title, credit value, module lead name and so on. It uses that data to comprise a single string, which alongside a single keyword is piped into a pre-processing unit, which uses NLTK to lemmatise the given strings. Lastly, the algorithm checks whether or not that keyword is present in any text data in a particular module, if so, it stores it into the matchedModulesSDG.json file.
Scopus Matching
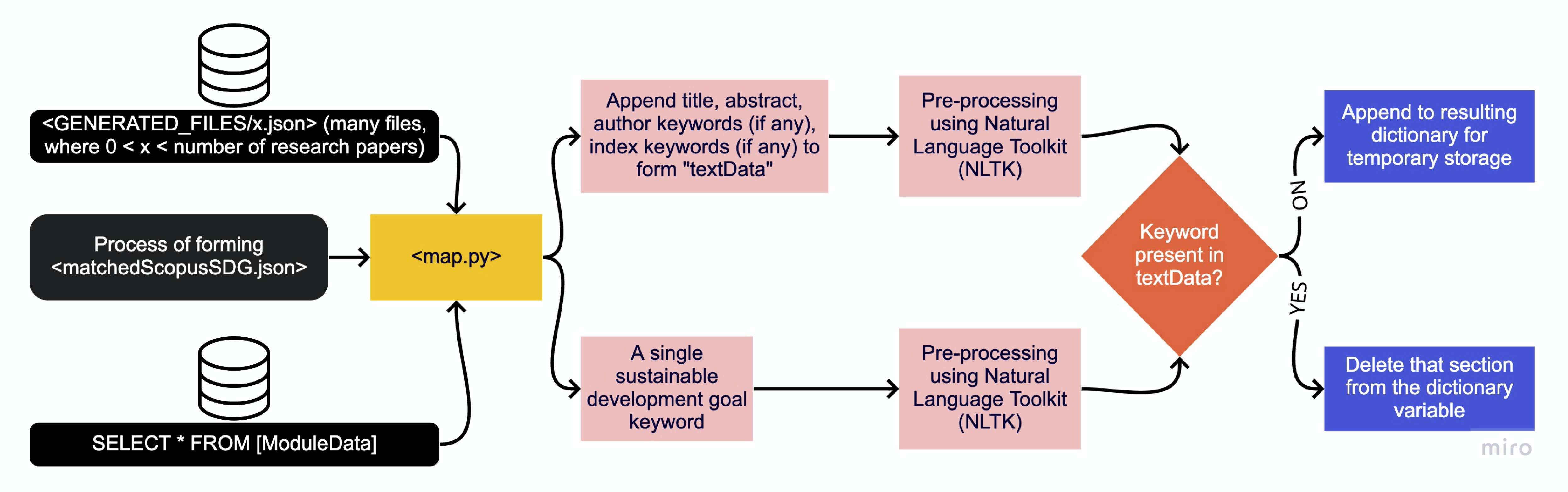
Diagram above illustrates a similar to the Module Catalogue to SDG Mapping, but this time it matches Scopus Research Publications to the sustainable development goals. The only difference is the type of data considered. Scopus provides more details about a particular publication, therefore, it allows for greater comparison and a more accurate matching. In this case, data points like abstract, title, author keywords, index keywords and subject area keywords are considered during string comparison. As a result, it generates the matchedScopusSDG.json file for further development.
Scopus Data Generation
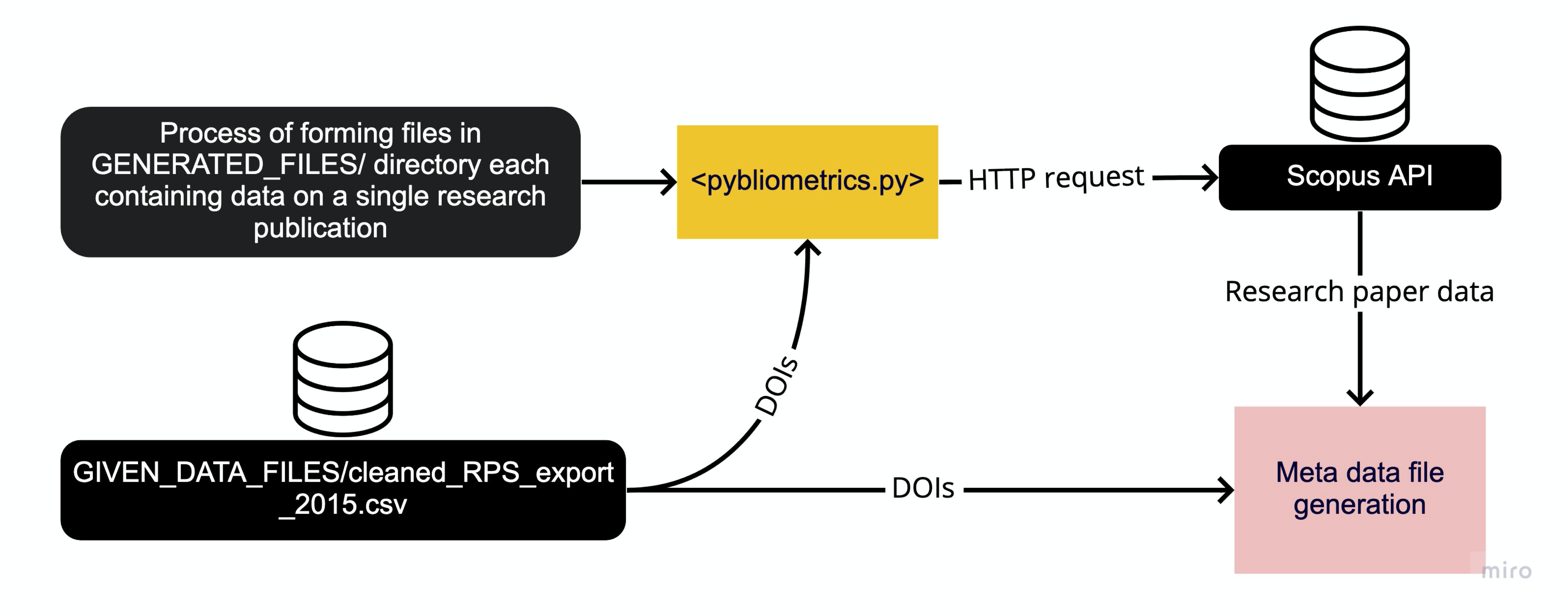
Diagram above illustrates the formation of the underlying dataset - common to all members of our client group. Therefore, the pybliometrics.py program carries out numerous tasks including reading individual research publication identifiers (DOIs) from the Research Publication Service (RPS) to act as a basis for the Scopus API request using the Python “requests” library
UCL Module Catalogue Keyword Extraction

Unlike Scopus publication data, where most papers have assigned keywords, catalogue modules are unlabelled. Hence, in order to apply the Latent Dirichlet Allocation algorithm called GuidedLDA, it is necessary to extract keywords that are representative of that particular module. Diagram above shows the processing stages of the access_module_data.py script. Firstly, it uses a database written by previous scrips to organise module metadata, then concatenates any strings that will be used. NLTK is used to preprocess the text data, which is then piped into the Term Frequency–Inverse Document Frequency (TF-IDF) vectoriser to perform a numerical statistic which will indicate the significance of each word, essentially demonstrating how reflective that word is of a particular collection of text data. Consequently, top 5 were taken, excluding any that have a significance less than 0.001. The resulting keywords, alongside the module identifications string are written to the ModuleKeywords database table hosted in Microsoft Azure server. The module identification string is specified as a primary key for ease of data retrieval.
NLP – Natural Language Processing
Description
The process of mapping UCL modules to UN SDGs (Sustainable Development Goals) is carried out using the semi-supervised GuidedLDA algorithm, described in the Research section. The GuidedLDA library uses Latent Dirichlet Allocation internally with topic seeds, which guide the algorithm and help it converge around those seeds (SDG keywords). The topic seeds are only used during initialization, whereby the seed words are much more likely to be matched with their corresponding topic seed. (Link to Source)
Natural Language Processing
The first stage is to pre-process the data using Natural Language Processing (NLP) techniques.
Normalization: remove punctuation and separate words between forward slashes.
Tokenization: convert text into sentences and those sentences into lowercase tokens, remove stopwords and words less than 3 characters.
Lemmatization: change words in future and past tenses to present tense and words in third person to first person.
Stemming: chops off the end of words and reduces them into their root form.
For this, we will use the NLTK and gensim libraries for pre-processing the module descriptions. The gensim API provides simple pre-processing methods for converting a document into a list of lowercase tokens and stopwords. NLTK provides more stopwords, a part of speech tagger, the WordNetLemmatizer class for lemmatization and SnowballStemmer class for stemming. The CountVectorizer or TfidfVectorizer classes from the sci-kit learn machine learning library are used to create a document-term matrix. This matrix forms the features of our model. The CountVectorizer class converts a collection of raw text documents to a matrix of token counts, whereas the TfidfVectorizer class converts the raw documents to a matrix of TF-IDF features.
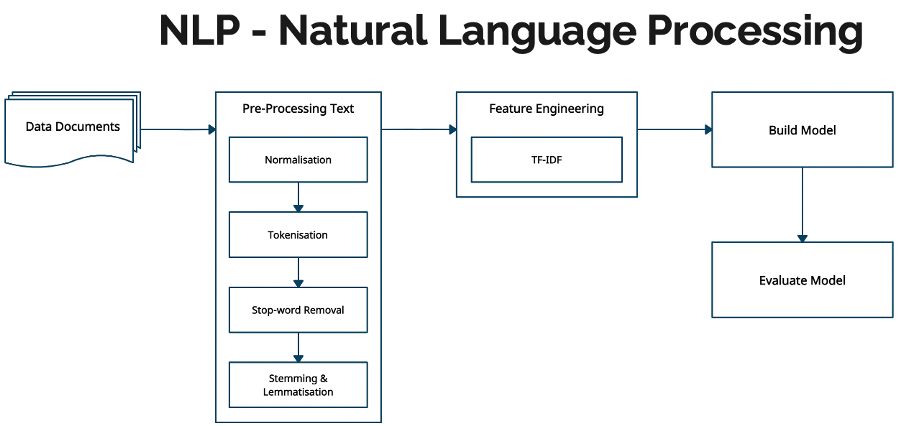
The Feature Engineering block implements the CountVectorizer or TfidfVectorizer classes to create a document term matrix. The Build Model block implements the GuidedLDA algorithm.
GuidedLDA
The diagram below demonstrates how GuidedLDA can be applied to map UCL modules to UN SDGs. The input consists of documents which are a substring of the module description for 4 different UCL modules and synthetic SDG-specific keywords for 17 different SDGs (numbering is not accurate). The output consists of topics with a set of words weighted by how important a word is for a given topic and documents with a set of topics weighted by how likely a topic is related to a given document. We did not train a model for this dummy dataset, but merely made-up the inputs and outputs but is supposed to demonstrate how the mapping will work.

Applying Natural Language Processing to the corpus produces a bag of words model for each document followed by a document-term matrix using CountVectorizer or TfidfVectorizer. The words are randomly assigned a topic but are largely influenced by the SDG-specific keywords. For example, the word marine in MECH0019 has a greater chance of being assigned to SDG 3 than SDG 1 because marine ∈ {marine, fishing, coastal, coral reef} which are the keywords for SDG 3. Following the random topic assignment, a word-topic matrix is produced where each cell is the number of times a word has been assigned to a topic and a document-topic matrix is produced where each cell is the number of times a topic comes up in a particular document.
Following the algorithm for GuidedLDA in the research section, it computes the proportion of words in a document that are assigned to a topic and the proportion of assignments to a topic across all documents that come from a particular word. Now, update the probability of a word belonging to a topic as the product of these two values and reassign a topic for the word. This procedure only counts as one iteration for the GuidedLDA. In practice, we train our model on hundreds of iterations to help it converge, yielding much more accurate results.
For the dummy dataset example, the GEOG0036 module on Water and Development in Africa is most related to SDG 1: No Poverty with a score of 0.5 and the MECH0019 module on Ocean Engineering Fundamentals is most related to SDG 3 with a score of 0.9. This makes the most sense because the keywords for SDG 3 are {marine, fishing, coastal, coral reef} which is meant to represent the SDG Goal 14 on Life Below Water - “Conserve and sustainably use the oceans, seas and marine resources for sustainable development.”
NLTK – Natural Language Toolkit
The NLTK – Natural Language Toolkit has advantages over PyTorch, making the code much more condense, manageable, and ease of implementation for NLP.
NLTK feature include tokenization, named-entity recognition, text classification, text tagging and RAKE – Rapid Automatic Keyword Extraction which is used for mapping keywords to UCL modules listed in the module catalogue.
NLTK – Natural Language Toolkit
Supervised Learning – Support Vector Machine
The purpose of using a supervised machine learning algorithm, such as the SVM, is to reduce the number of false positives predicted by our NLP model and to make accurate predictions on textual field data that it has never seen before – which forms our Universal SVM page on the Django web application.

While we want to have a high accuracy, because we believe the majority of topic modelling (and string search) results are accurate, we don’t want to cause overfitting because we know already that some of our LDA model predictions (and string search predictions) are incorrect.
Support Vector Machine (SVM) is a linear classifier that uses SGD (Stochastic Gradient Descent training) with the scikit-learn machine learning library. We used the SGDClassifer class with the loss function set to ‘hinge’, which gives us a linear SVM model. We did try setting the loss to ‘log’ as well, which gives logistic regression, however this resulted in a lower accuracy than the linear SVM model:
| Model |
Accuracy |
|---|
| SVM |
83% |
| Logistic Regression |
77% |
For training our SVM, we instantiate a Pipeline for sequentially applying a list of transforms (TF-IDF vectorization) with a final estimator, which only needs to be fit (trained). We use the CalibratedClassifierCV as a wrapper around SGDClassifier because it allows us for predicting probabilities – which aren’t possible with SGDClassifier using a ‘hinge’ loss function (a linear SVM model). The calibrations are based on the predict_proba method, which returns an array of probability estimates for each class (SDG).

We partition the dataset (containing UCL modules and research publications) using a 70-30% split. We take 70% of the data for the training set and 30% of the data for the test set. To train the model, we call fit on our Pipeline object and return the description and labels for the training set and test set.
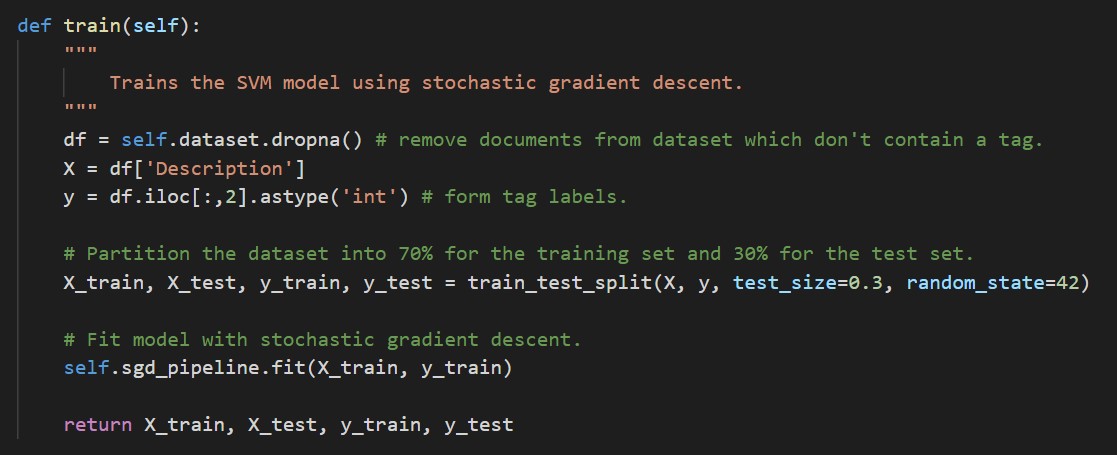
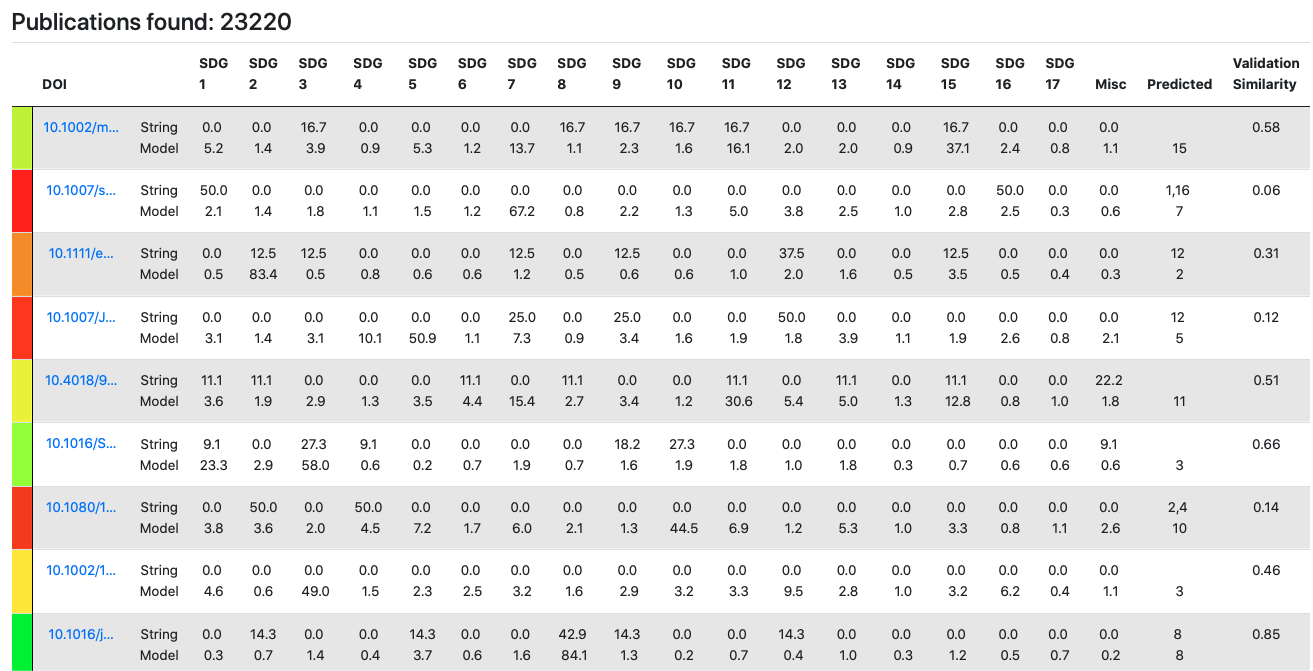
Once our model has been fit, we can apply our model to make predictions on any textual data field by pre-processing the text and calling the predict_proba method. In this naïve example, we predict an SDG which has the highest probability, however in our Django web application, we use a 30% tolerance and display the probability distribution as a table.

Django Search Engine Web Application
As part of one of the client requirements, we are to interface the data gathered onto a web application. Although many alternatives exist, Django stands out as a best-suited solution for the task at hand. Below one may find an overview desired and the basic functionality the web application provides:

Since all the data scraped is stored in the Azure SQL Server, it is necessary to migrate the data into the Django SQLite database. Hence, we start by defining a model for the module data:
Department_Name = models.CharField(max_length=200)
Department_ID = models.CharField(max_length=100)
Module_Name = models.CharField(max_length=200)
Module_ID = models.CharField(max_length=100)
Faculty = models.CharField(max_length=200)
Credit_Value = models.IntegerField(default=0)
Module_Lead = models.CharField(max_length=100, null=True, blank=True)
Catalogue_Link = models.CharField(max_length=200)
Description = models.CharField(max_length=1000, null=True, blank=True)
Last_Updated = models.DateTimeField
This creates the fields that match the MySQL data type fields:
CREATE TABLE ModuleData (
Department_Name VARCHAR(150),
Department_ID VARCHAR(150),
Module_Name VARCHAR(150),
Module_ID VARCHAR(150) PRIMARY KEY,
Faculty VARCHAR(100),
Credit_Value FLOAT,
Module_Lead VARCHAR(100),
Catalogue_Link VARCHAR(MAX),
Description VARCHAR(MAX),
Last_Updated DATETIME DEFAULT CURRENT_TIMESTAMP
);
Upon its creation, a Django views.py is used to gather the objects, and pressing the “Reload Data” button makes a query to the Azure SQL tables to copy over the data and populate the Django objects (unless they already exist in the records). A similar process occurs for the research publications scraped from Scopus platform. Next step involves creation of the index.html, module.html and publication.html for the Django class-based views, allowing a creation of dynamic details page display without creation of an HTML page for each object specifically.
Publication Detailed View Page
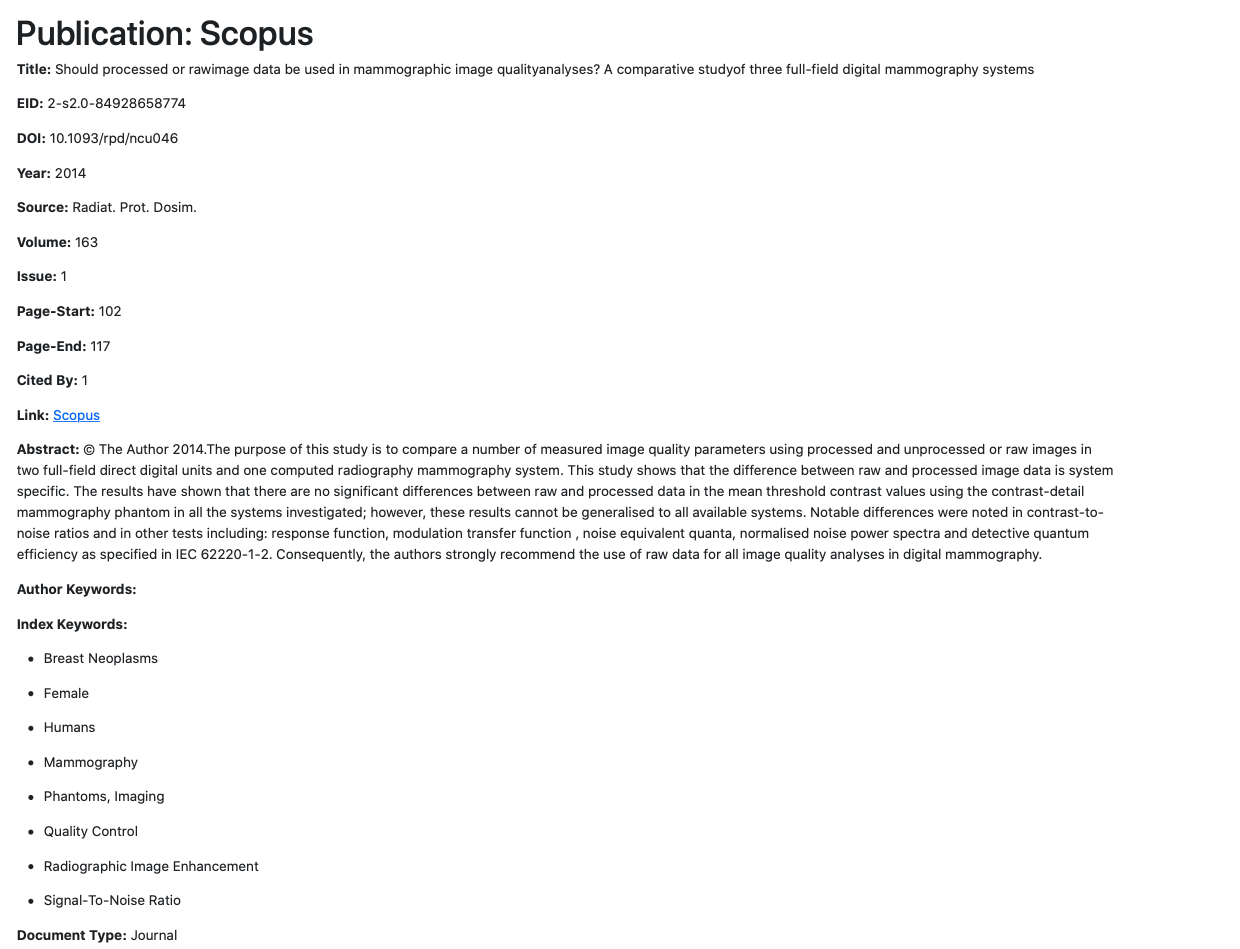
Publication Detailed View Page

The next step is to implement the most important aspect - search. In the case of two sources of data, we include a checkbox for selecting either source or both sources. We still use the Django views.py to create a function to perform the search across all data fields (any text-format piece of data). Upon running the search, Django utilises filtering function to produce a dictionary of objects that match the criteria and are then passed onto the index.html, where embedded Python code deals with display manner and style. Subsequently, we produce the following product:
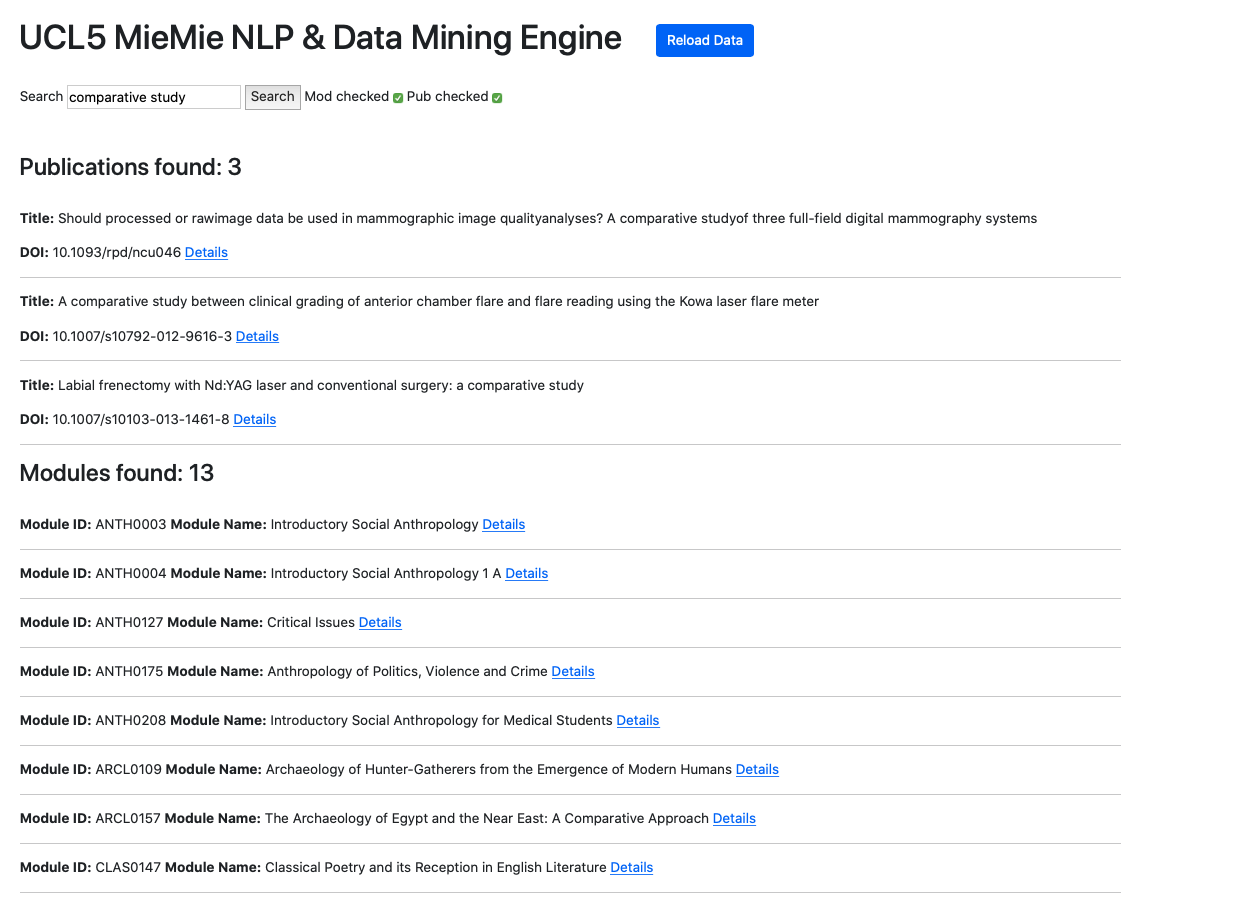
References
[1] 2020. Keyword-Based Topic Modeling And Keyword Selection. [ebook] Evanston, Illinois: Northwestern University. Available at: https://arxiv.org/pdf/2001.07866.pdf [Accessed 10 December 2020].
[2] Lagus, K. and Kaski, S., 2020. Keyword Selection Method For Characterising Text Document Maps. [online] Helsinki, Finland: Helsinki University of Technology, Neural Networks Research Center. Available at: https://users.ics.aalto.fi/krista/papers/lagus99icann.pdf [Accessed 10 December 2020].
[3] Montantes, J., 2020. Getting Started With NLP Using The Pytorch Framework - Kdnuggets. [online] KDnuggets. Available at: https://www.kdnuggets.com/2019/04/nlp-pytorch.html [Accessed 10 December 2020].
[4] Nascimento, A., 2020. How To Cook Neural Nets With Pytorch. [online] Medium. Available at: https://towardsdatascience.com/how-to-cook-neural-nets-with-pytorch-7954c1e62e16 [Accessed 10 December 2020].
[5] Pytorch.org. 2020. TOURCH.NN — Pytorch 1.7.0 Documentation. [online] Available at: https://pytorch.org/docs/stable/nn.html#recurrent-layers [Accessed 10 December 2020].
[6] Spacy.io. 2020. Training A Text Classification Model. [online] Available at: https://spacy.io/usage/training#textcat [Accessed 10 December 2020].